Real-Time Fraud Detection at the Edge: How Banks Stop Threats in Milliseconds
Why moving fraud decisions closer to transactions changes outcomes, not just architecture.
The New Fraud Reality: Speed Beats Accuracy Alone
In fraud prevention, timing is everything.
A transaction approved in 40–70ms can stop a mule account before funds move.
The same decision made in 250–400ms often arrives after the damage is done.
Banks learned this the hard way as digital payments exploded. Cloud-only fraud stacks were accurate, but too slow. By the time a centralized model scored a transaction, downstream systems had already committed.
The shift: run fraud inference at the edge, where the transaction happens.
This is not about replacing the cloud. It is about putting milliseconds where they matter most.

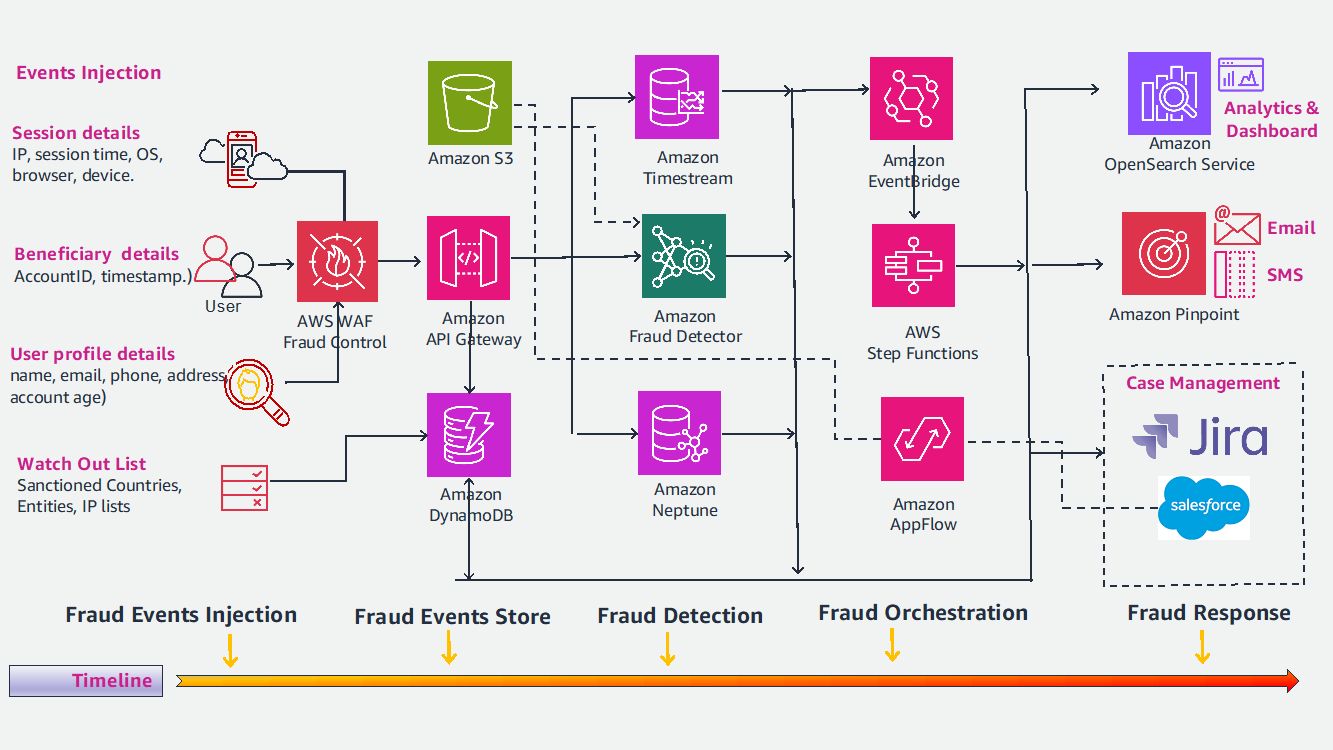
1. Why Cloud-Only Fraud Detection Falls Short
A) Latency kills signal quality
Fraud signals decay fast:
- Velocity patterns change within seconds
- Device fingerprints lose value after retries
- Session context fragments across hops
A 300ms delay is not just slow. It is less accurate.
B) Network variability creates blind spots
Cloud routing depends on:
- Cross-region hops
- ISP congestion
- Peak-hour spikes
Fraud systems need predictable latency, not average latency.
C) Regulatory pressure favors local decisions
Many regulators now expect:
- Local processing of payment metadata
- Minimal cross-border sharing
- Explainable, auditable decisions
Edge deployments satisfy all three.
2. What “Fraud at the Edge” Really Means
Edge fraud detection does not mean training big models on small devices.
It means:
- Inference at the edge
- Training in the cloud
- Policy and orchestration across both
Typical split
- Cloud: feature engineering, model training, global risk analytics
- Edge: transaction scoring, rule enforcement, immediate actions
Think of the edge as a decision executor, not a data scientist.
3. Where Edge Fraud Delivers Immediate Wins
A) Card payments and UPI
- Sub-50ms scoring
- Local velocity checks
- Region-specific heuristics
B) ATM withdrawals
- Withdrawal amount thresholds
- Device health checks
- Geo consistency
C) Account takeovers
- Login anomaly detection
- Session hijack signals
- Device mismatch
D) Real-time lending
- Synthetic identity screening
- Behavioral risk scoring
- Instant approvals or step-up authentication
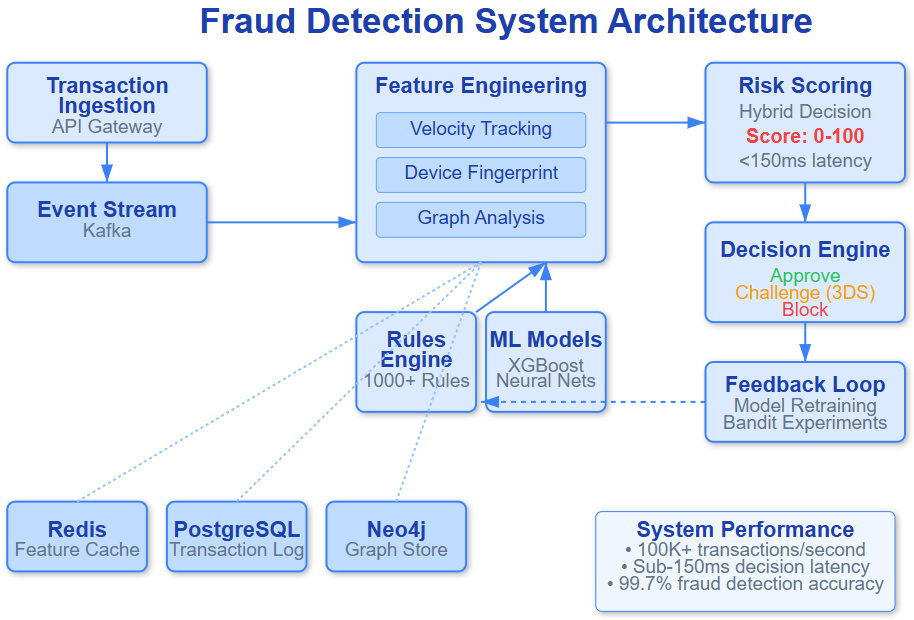
4. The Edge Fraud Architecture (Simplified
Step 1: Transaction hits edge
ATM, POS, mobile app, browser, or payment gateway.
Step 2: Local feature extraction
- Device fingerprint
- Velocity counters
- Geo proximity
- Historical risk cache
No cloud calls yet.
Step 3: ML inference at edge
A compact model scores risk in 5–20ms.
Step 4: Policy decision
- Approve
- Decline
- Step-up (OTP, biometric, delay)
Step 5: Async cloud sync
Edge sends:
- Decision metadata
- Feature summaries
- High-risk samples
Cloud updates global models later.
5. Models That Actually Work at the Edge
Edge fraud models must be:
✔ Small
✔ Deterministic
✔ Fast
✔ Interpretable
Common choices
- Gradient-boosted trees
- Logistic regression ensembles
- Small neural nets
- Rules + ML hybrids
Interesting fact:
Several Tier-1 banks report better outcomes with hybrid rules + small ML models at the edge than with large cloud-only deep models.
Why? Because speed and locality beat raw complexity.
6. A Real Bank Story: 72% Faster Decisions
A large APAC retail bank faced:
- 280ms average fraud decision time
- High false positives on peak days
- Rising UPI fraud attempts
What they changed
- Deployed fraud inference nodes at regional edges
- Cached velocity and device features locally
- Limited cloud calls to high-risk escalations
Results
- Decision time: 280ms → 78ms
- Fraud detection rate: +11%
- False positives: −18%
- Customer complaints: −22%
No model rewrite. Just architectural placement.
7. Handling Model Drift and Updates at the Edge
This is where many teams struggle.
Best practices
- Train centrally, deploy locally
- Version models like firmware
- Canary releases per region
- Automatic rollback on metric degradation
- Nightly drift reports
Edge nodes should never auto-update blindly.
8. Security and Trust at the Edge
Fraud systems are prime targets.
Edge security must include:
- Secure boot and signed models
- Encrypted inference artifacts
- Tamper detection
- mTLS between edge and cloud
- Local audit logs
Key rule:
If an attacker compromises an edge node, the blast radius must stay local.
9. Explainability and Compliance
Regulators increasingly ask:
“Why was this transaction declined?”
Edge fraud systems should produce:
- Feature-level explanations
- Rule hit summaries
- Confidence scores
These are sent to the cloud for:
- Audit trails
- Dispute resolution
- Regulatory reporting
Edge does not mean opaque.
10. Cost Benefits Most Teams Miss
Running fraud at the edge often reduces:
- Cloud inference costs by 40–60%
- Network egress significantly
- Peak-hour scaling stress
Edge nodes handle bursts naturally, without overprovisioning central systems.
11. 30-60-90 Day Adoption Plan
Days 0–30
- Identify top 3 fraud decision points
- Measure current p95 latency
- Select edge inference framework
Days 31–60
- Deploy one model to edge
- Add local feature caching
- Implement async cloud sync
Days 61–90
- Roll out to additional regions
- Introduce canary updates
- Add explainability pipelines
- Run fraud chaos tests
12. Common Pitfalls to Avoid
❌ Pushing full models to the edge
✔ Use compact inference models
❌ Treating edge as always online
✔ Design for intermittent sync
❌ Ignoring observability
✔ Track false positives, drift, latency locally
❌ Centralizing every decision
✔ Escalate only high-risk cases
Final Thought
Fraud prevention is a race against time.
Banks that rely solely on cloud analytics will always be reacting.
Banks that move decisions to the edge act first.
Edge-based fraud detection is not about being faster for the sake of speed.
It is about making the right decision before fraud becomes irreversible.

